Introduction to the scale of our operations
Our backend systems play an essential role to provide our customers with up to date data for the following purposes:
- Document Search Index: gather latest news from the web and index them to our AI-powered search engine
- Time Series: measure recent data points in our time series engine
- Alerts: evaluate alerts conditions and notify our customers
So, whenever our customers create a new measurement, an augmented document search index (including audio & video processing), or an alert rule, this is the component that is responsible for collecting and processing all the data.
To get an idea of the scale we handle in our time series systems for example:
- we track around 1,000 social profiles, channels and authors,
- not only their main profile metrics like follower counts,
- but we track each of their posts for 72 hours,
- all metrics, including likes, comments, shares, etc., and
- we measure all of those every single hour.
These are millions of measurements in total every one or two days, based on social activity. According to our earliest estimations, we needed hundreds of hours of compute each day to be able to process all requests.
Our infrastructure is built on serverless and container-based, automatically scaling systems, which allows us to handle any scale we need. But shortly after our product launch, we easily found ourself scaling out to 1,000 machines each hour to handle the ever growing load our customers need. And while it still serves our needs, to be able to provide competitive pricing, it was time to look into what can we do to reduce our resource consumption and overall operational cost.
Optimization techniques
While our code was not necessarily written in a bad way, it was written like regular business logic, intentionally not optimized for performance upfront, but for time to market and maintainability.
Our team consists of exceptional talent, who have experience in building and operating even larger systems, of which one specifically had to be able to scale out to handle tens of millions of requests per peak minutes.
We chose .NET for our backend systems because it is mature enough to provide a perfect balance between maintainability and performance, so we had the right tools already available to optimize lower layers and hot paths for cutting edge performance.
We employed various techniques from macro to micro optimizations in our codebase, including:
- Fine-tune scaling rules for better resource utilization
- Batch remote calls to reduce round trips
- Parallelize processing to fill in idle CPU time
- Aggressive reduction of heap allocations and garbage collection pressure
- Memory pooling
- Using lower-level constructs like Spans to avoid unnecessary copying
- Optimized algorithms
- Specialized serialization at compile time using Source Generators for most frequently used remote services
- Take advantage of hardware accelerated, vectorized operations provided by the framework
- Optimized collection types for search
- We have developed more than 20 specialized data structures fine tuned for specific use cases
- Other tricks to spare a few checks and bytes here and there
We do a lot of text processing (reading news from web sites, constructing prompts for LLMs, etc.), and while one might think that text processing is easy, it is actually one of the most expensive operations in our codebase:
- Most web pages are not only human readable text, but they also contain a lot of code prerendered in the HTML for better startup times, so their size ranges from a few hundred kilobytes to even several megabytes. And since regular Strings are immutable, even a small change in the text can lead to a lot of copying and moving megabytes of data back and forth in memory.
- The same applies for constructing prompts. Some modern LLMs support context window sizes from a few 100k to even a million tokens, which can easily translate to several megabytes of text.
Results
One of the most frequent operations in our codebase is to reduce HTML content and extract meaningful parts. Then the document is sent for further processing for different purposes: parsing data points, or adding it to a prompt as context for an LLM.
We have completely rewritten our naive HTML minifier to an optimized version with zero heap allocations and faster algorithms. To compare the results, we run micro benchmarks to measure the actual performance gains:
{ "tooltip": { "trigger": "axis", "axisPointer": { "type": "shadow" } }, "xAxis": [ { "type": "category", "axisTick": { "show": false }, "axisLabel": { "formatter": "{value} KB" }, "data": ["50", "150", "1024"] } ], "yAxis": [ { "type": "value", "axisLabel": { "formatter": "{value} KB" } } ], "series": [ { "name": "Unoptimized", "type": "bar", "barGap": 0, "data": [617, 1174, 2784], "itemStyle": { "color": "#aa1410" } }, { "name": "Optimized", "type": "bar", "emphasis": { "focus": "series" }, "label": { "show": true, "position": "top", "distance": 32, "formatter": "{c} KB" }, "itemStyle": { "color": "#85dbc2" }, "data": [27, 62, 41] } ] }
| Method | Mean | Error | Gen0 | Gen1 | Gen2 | Allocated |
| Old_50KB | 1,219.9 us | 15.40 us | 35.1563 | 7.8125 | - | 616.74 KB |
| New_50KB | 978.9 us | 9.55 us | - | - | - | 26.88 KB |
| Old_150KB | 5,243.1 us | 89.14 us | 109.3750 | 62.5000 | 62.5000 | 1,173.81 KB |
| New_150KB | 2,792.7 us | 23.11 us | - | - | - | 61.92 KB |
| Old_1MB | 37,389.5 us | 394.65 us | 428.5714 | 428.5714 | 428.5714 | 2,784.44 KB |
| New_1MB | 4,674.2 us | 16.30 us | - | - | - | 41.06 KB |
We gained up to 10x speed up in compute and almost 100x reduction in memory for large HTML documents with no more garbage collection pressure to carry on.
This is an easy to demonstrate example but only one of the many optimizations we have done.
The following chart shows the overall impact of our optimizations on the number of machines we need to run our backend systems:
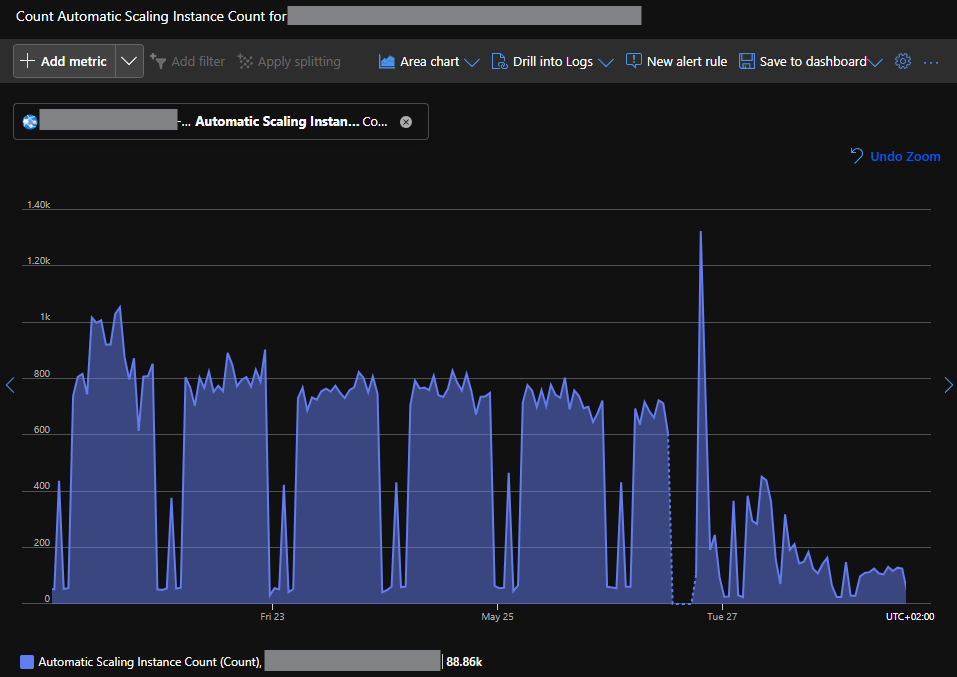
The number of machines we used over time We were able to reduce the number of machines we need each hour to handle the load from 1,000 machines to around 100 machines, which is a 10x reduction in resource consumption.
We were also able to reduce our overall memory consumption even more, we don't need TBs of memory (in total) anymore, but our total memory needs dropped by 20-40x.
While there is still a lot of room for further optimizations, we are very happy with the results we have achieved so far. The new code is going to be a solid foundation for our future growth and we are confident that we can handle even larger scale with the same or even less resources.
Peter
Chief Technology Officer